

本文使用的工具集合Ollama + ChatBox:
百度云链接: https://pan.baidu.com/s/1CgUvYdPtxjt8oqt1cb5ynw 提取码:
一、引言
随着人工智能技术的快速发展,大语言模型(LLM)在各个领域的应用越来越广泛。DeepSeek-R1 是一款支持中英文双语处理的大型语言模型,具有多种版本以满足不同用户的需求。本文将详细介绍如何在 Macos Monterey 12.7.6 系统上部署 DeepSeek-R1:7B 模型,并通过 ChatBox 实现可视化交互。
二、DeepSeek-R1 不同版本的区别
DeepSeek-R1 系列模型根据参数量的不同分为多个版本,每个版本在性能、适用场景和硬件需求上有所差异。以下是部分版本的对比:
| 版本 | 参数量 | 特点 | 适用场景 | 硬件需求(CPU/内存) |
|---|---|---|---|---|
| DeepSeek-R1-1.5B | 1.5B | 轻量级模型,资源消耗低 | 短文本生成、基础问答 | 4核处理器、8GB内存 |
| DeepSeek-R1-7B | 7B | 平衡型模型,性能较好 | 文案撰写、表格处理、统计分析 | 8核处理器、16GB内存 |
| DeepSeek-R1-8B | 8B | 性能略高于 7B | 中等复杂度任务 | 8核处理器、16GB内存 |
| DeepSeek-R1-14B | 14B | 高性能模型,适合复杂任务 | 企业知识管理、合同分析 | 16核处理器、32GB内存 |
| DeepSeek-R1-32B | 32B | 高精度复杂推理 | 专业领域(金融、医疗) | 32核处理器、64GB内存 |
| DeepSeek-R1-671B | 671B | 超大规模基础模型 | 多模态任务、科研计算 | 高性能计算集群 |
选择建议:
-
如果硬件资源有限(如个人开发者或普通工作站),推荐使用 7B 或 8B 版本。
-
对于复杂任务或企业级应用,可选择 14B 或 32B 版本。
三、本地部署 DeepSeek-R1:7B
本文以 Macos Monterey 12.7.6 系统为例,采用 Intel Core i5 处理器进行部署。由于 DeepSeek-R1:7B 对硬件需求适中,适合在该配置上运行。
-
安装 Ollama
-
访问 Ollama 官方网站,下载适用于 Macos 的安装包。
-
安装完成后,打开终端运行以下命令验证安装是否成功:
ollama --version
-
-
拉取 DeepSeek-R1:7B 模型
-
在终端运行以下命令下载并加载模型:
ollama run deepseek-r1:7b 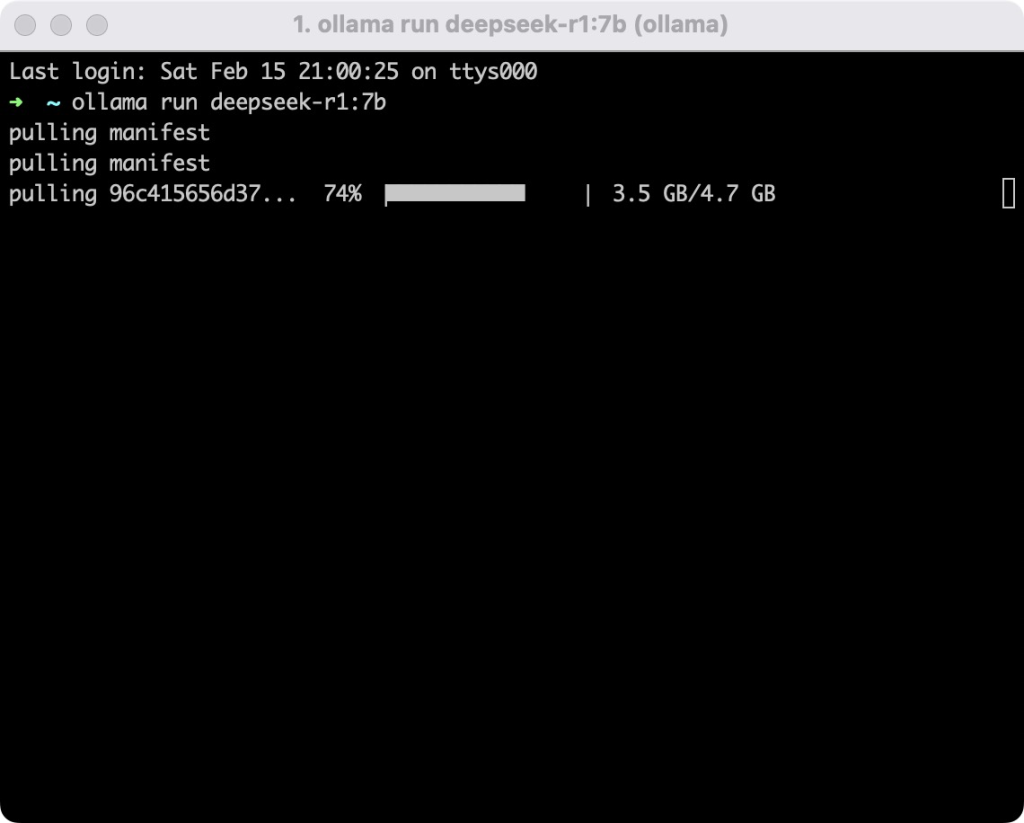
-
模型下载完成后,终端会显示“>>> Send a message…”,表示模型已成功加载。
-
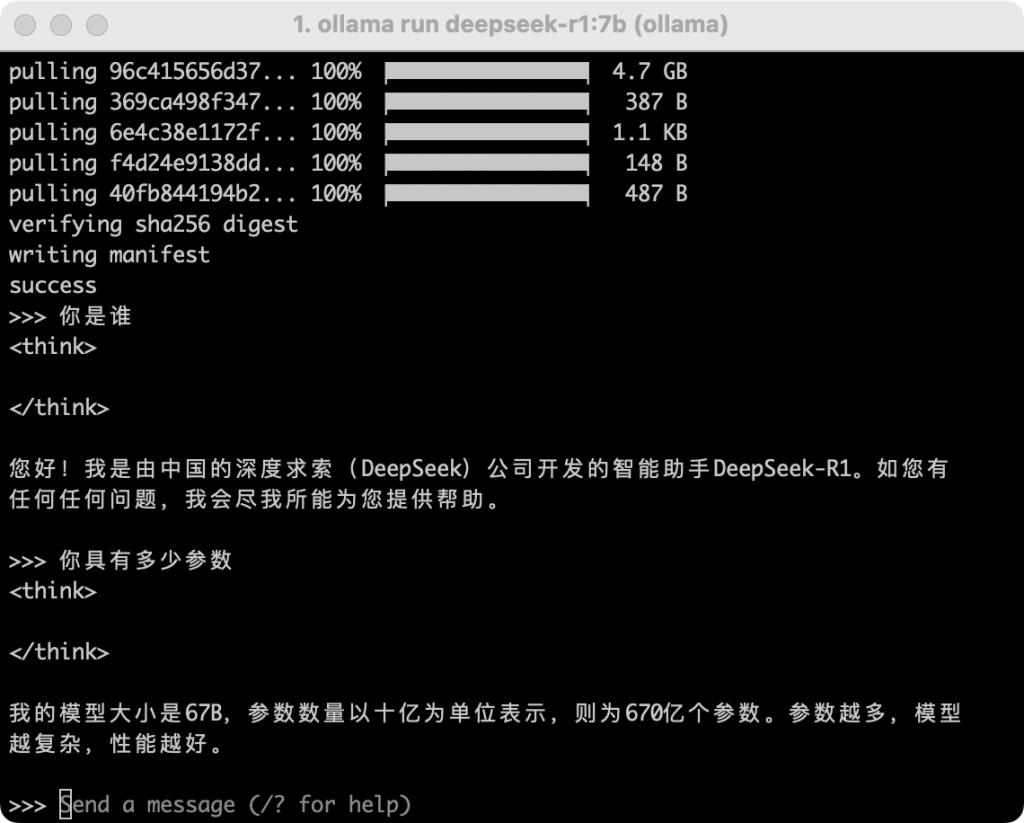
-
-
配置量化(可选)
-
为了降低内存占用,可以使用 4-bit 量化技术。运行以下命令:
ollama run deepseek-r1:7b-q4_0
-
四、基于 ChatBox 的可视化部署
ChatBox 是一款轻量级的客户端工具,支持与 Ollama 本地模型的无缝连接。
-
安装 ChatBox
-
访问 ChatBox 官方网站,下载适用于 Macos 的安装包。
-
安装完成后,将 ChatBox 拖入 Applications 文件夹。
-
-
配置 ChatBox
-
打开 ChatBox,选择“OLLAMA API”。
-
在配置页面中填写以下参数:
-
API Endpoint:
http://localhost:11434 -
Model:选择已加载的
deepseek-r1:7b模型。
-
-
保存配置后返回聊天窗口。
-
-
测试模型
-
在 ChatBox 聊天窗口中输入问题(如“写一个 Python 快速排序算法”),测试模型的响应。
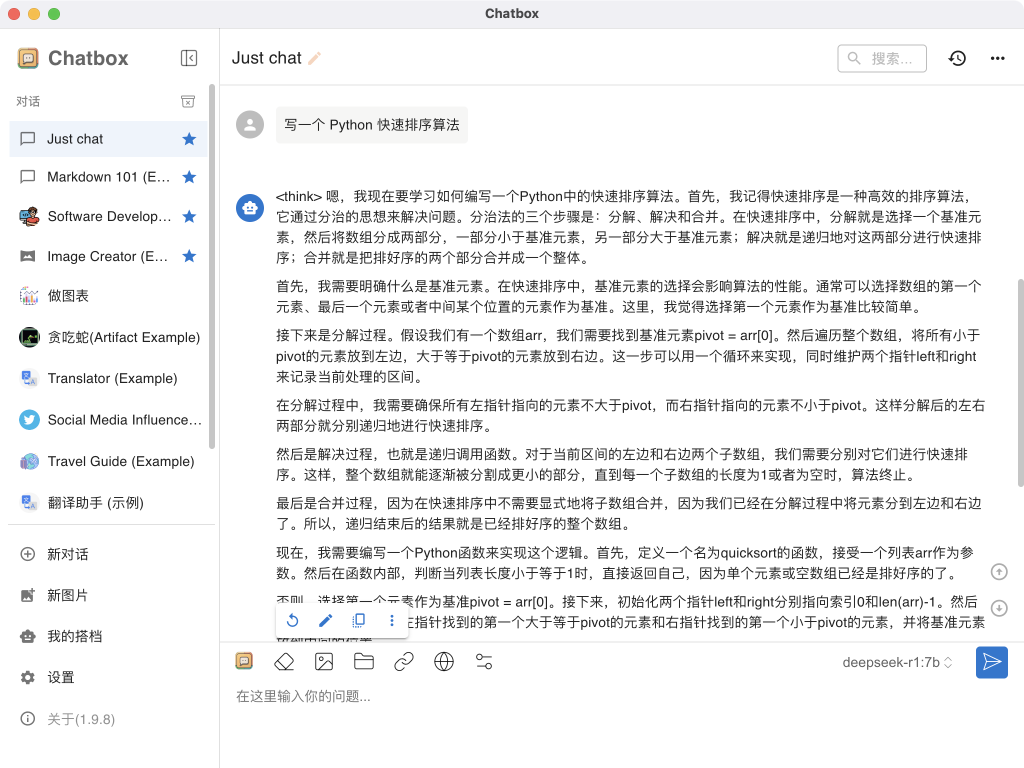
-
五、总结
通过上述步骤,我们成功在 Macos Monterey 12.7.6 系统上部署了 DeepSeek-R1:7B 模型,并通过 ChatBox 实现了可视化交互。DeepSeek-R1:7B 模型在性能和资源消耗之间取得了良好的平衡,适合在普通工作站上运行。借助 ChatBox 的可视化界面,用户可以更便捷地与模型进行交互,无需复杂的命令操作。
希望本文能为希望在本地部署 DeepSeek 的用户提供参考。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END



暂无评论内容